안녕하세요.
이번엔 iOS 15부터 새로 추가된 TabulaData 프레임워크에 대해 알아볼게요.
# 1. TabulaData 프레임워크란?
TabulaData 프레임워크란 무엇이냐
Import, organize, and prepare a table of data to train a machine learning model.
머신러닝을 위해 데이터 테이블을 import, organize, prepare 하는 것.
TabulaData에서 말하는 데이터는 row, column으로 이루어진 테이블을 말해요.
그리고 TabulaData 프레임워크를 통해 그 데이터에서 유의미한 결과를 얻도록 가공하는 것이죠.
# 2. DataFrame
row와 column으로 이루어진 테이블을 DataFrame이라고 해요.
직접 DataFrame을 만들어볼게요.
우선 TabulaData를 import 해주고,
import TabularData
DataFrame을 생성해줍니다.
var dataFrame = DataFrame()
이로써, row와 column으로 이루어진 테이블의 기본 틀을 만든 것이에요.
테이블의 틀을 만들었으니, row와 column을 넣어줘야겠죠??
var dataFrame = DataFrame()
let idColumn = Column(name: "id", contents: [1, 2, 3])
let nameColumn = Column(name: "name", contents: ["Philip", "Tom", "Mike"])
let ageColumn = Column(name: "age", contents: [19, 25, 30])
dataFrame.append(column: idColumn)
dataFrame.append(column: nameColumn)
dataFrame.append(column: ageColumn)
id, name, age라는 Column을 만들어서 dataFrame에 넣어주면 끝입니다.
화면에 출력해볼까요??
print(dataFrame)

오오옷...👍 👍 👍
그냥 print만 하면 콘솔에 알아서 테이블 형태로 출력되는 것을 볼 수 있어요.
(TabulaData 프레임워크가 자랑하는 것 중에 하나입니다ㅎㅎㅎ)
그럼 Swift에서 제공하는 기본 type만 넣을 수 있냐?? 그건 아니에요.
Person이란 구조체를
struct Person {
var id: Int
var name: String
var age: Int
}
DataFrame에 넣어주면,
var dataFrame = DataFrame()
let personColumn = Column(name: "person", contents: [Person(id: 1, name: "Philip", age: 19), Person(id: 2, name: "Tom", age: 25), Person(id: 3, name: "Mike", age: 30)])
dataFrame.append(column: personColumn)
print(dataFrame)

깔끔하게 잘 들어갑니다ㅎㅎㅎ
이렇게 DataFrame을 직접 만들 수도 있지만,
TabulaData 프레임워크에는 csv 파일이나, json 파일을 읽어서 DataFrame으로 만들어주는 기능도 있습니다.
(여기에 샘플 csv 데이터 업로드해둘게요. 파일 이름은 oscar_age_male.csv 입니다.)
## 2.1. CSV 파일 읽기
oscar_age_male.csv 파일을 읽기 위해 fileUrl을 만들어주고,
guard let fileUrl = Bundle.main.url(forResource: "oscar_age_male", withExtension: "csv") else { return }
DataFrame에 넘겨주면 끝입니다.
var dataFrame = try! DataFrame(contentsOfCSVFile: fileUrl)
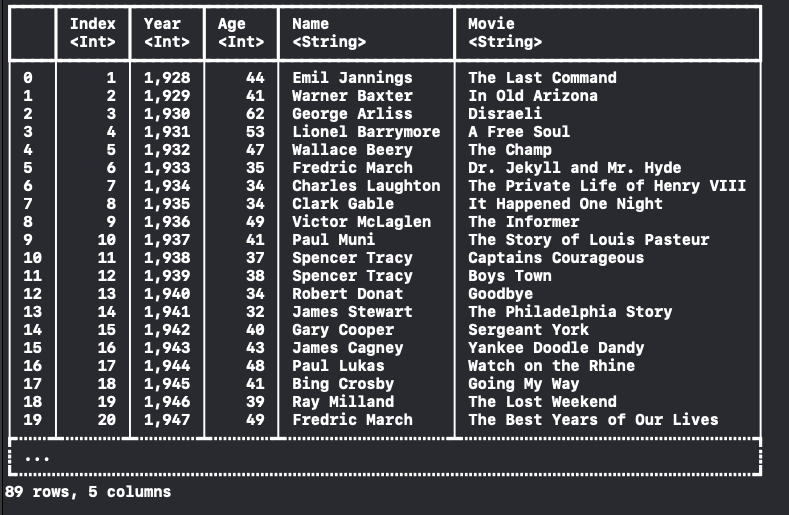
## 2.2 option 설정
CSV 파일을 읽을 때 CSVReadingOptions를 사용해서 option을 설정해줄 수 있어요.
CSVReadingOptions 생성자를 한 번 볼게요.

뭔가 겁나 많지만, 사실 별거 없어요.
- CSV 파일에 헤더가 있어?
- 어떤 값을 nil로 해줄까?
- 어떤 값을 true로 해줄까?
- 어떤 값을 false로 해줄까?
- 줄이 비어있으면 DataFrame에 포함시킬까?
- 구분자는 뭐야?
- ...
위처럼 CSV 파일을 읽을 때 꼭 고려해야 할 것들을 하나하나 설정을 해줄 수 있는 것이에요.
let options = CSVReadingOptions(
hasHeaderRow: false,
nilEncodings: ["", "nil"],
ignoresEmptyLines: true,
delimiter: ";"
)
let dataFrame = try! DataFrame(contentsOfCSVFile: fileUrl, options: options)
이렇게 설정을 했다면, 아래 규칙에 따라 fileUrl을 읽어올 것이에요.
그 파일은 헤더는 없고,
"", "nil" 은 nil로 쳐줘.
그리고 빈 줄은 DataFrame에 포함시키지 말고,
구분자는 ";" 이야.
뭔가 파라미터 명이 직관적인 거 같아서 전 좋더라구요ㅎㅎ...
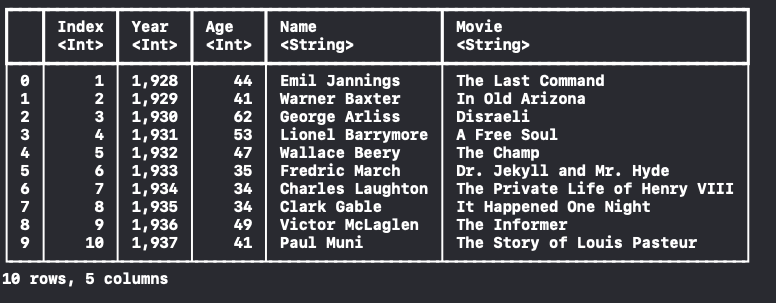
## 2.3 일부분만 가져오기
"row를 일부분만 가져오고 싶다!!"
할 때는 DataFrame에 rows argument를 사용합니다.
var dataFrame = try! DataFrame(contentsOfCSVFile: fileUrl, rows: 0..<10)
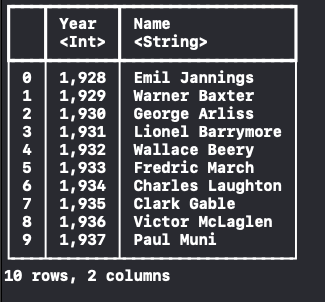
row 뿐만 아니라 특정 column만 가져오도록 할 수 있어요.
let dataFrame = try! DataFrame(contentsOfCSVFile: fileUrl, columns: ["Year", "Name"], rows: 0..<10)
## 2.4 타입 지정
TabulaData는 값을 읽을 때, 타입을 알아서 지정해줍니다.
그리고 integer, boolean 등 타입을 딱히 지정할 수 없을 때는 기본값인 string으로 설정해줍니다.
TabulaData가 데이터 타입을 지정할 때, 임의의 타입이 아닌 CSVType 중 하나의 타입을 사용하도록 직접 명시해줄 수 있어요.
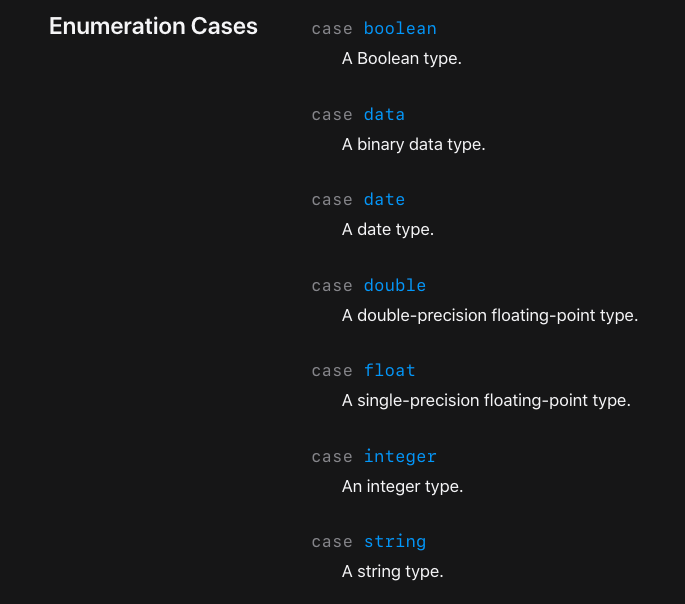
그리고 타입을 명시적으로 선언하면, 데이터를 읽어올 때 약간의 성능 향상이 있답니다ㅎㅎ
Year Column의 데이터를 Int 형 대신 Double 타입으로 읽어오도록 해볼게요.
let dataFrame = try! DataFrame(contentsOfCSVFile: fileUrl, types: ["Year":.double])
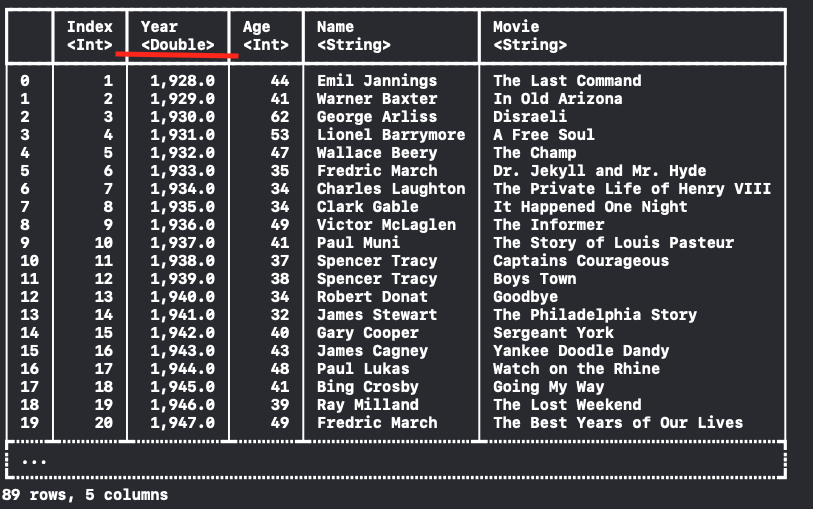
## 2.5 DataFrame 접근
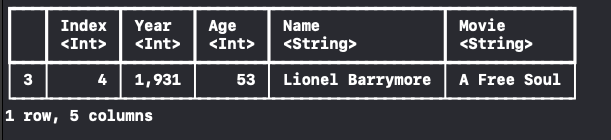
특정 row에 접근하고 싶으면, row subscript를 사용합니다.
let row = dataFrame[row: 3]
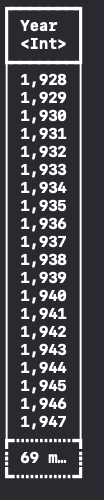
특정 column에 접근하고 싶으면, column subscript를 사용합니다.
let column = dataFrame[column: 1]
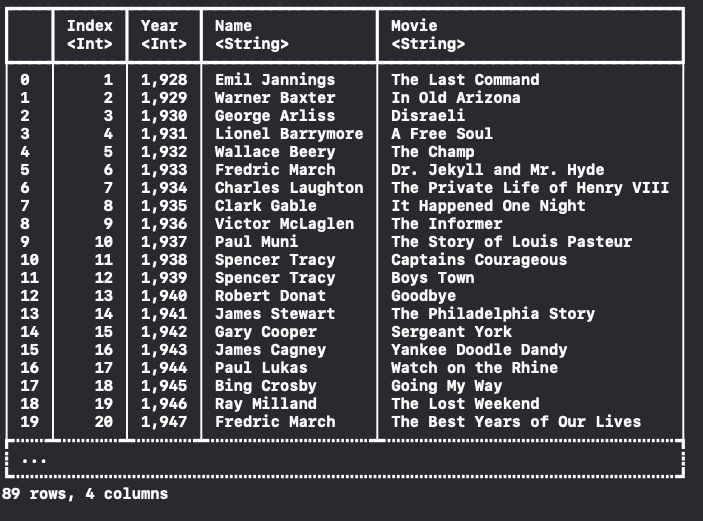
## 2.6 Column 삭제
removeColumn method를 사용하면 특정 column을 제거할 수 있어요.
removeColumn을 사용하면 DataFrame이 변경되는 것이기 때문에 let이 아닌 var로 선언해줘야 합니다.
var dataFrame = try! DataFrame(contentsOfCSVFile: fileUrl)
dataFrame.removeColumn("Age")
## 2.7 DataFrame filter
특정 조건으로 필터링할 수 있습니다. 이때 생성되는 타입은 Slice입니다.
Age > 60 인 row만 추출해볼게요.
let filtered = dataFrame.filter(on: "Age", Int.self) { $0! >= 60 }
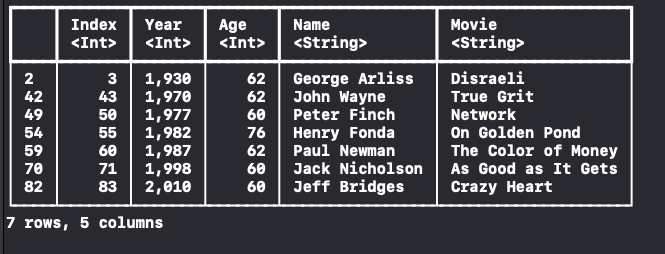
여기서 주의할 점이 있어요.
필터링한 데이터의 index는 0부터 시작하는 것이 아닌 2부터 시작합니다.
그래서 반복문을 돌릴 때는 아래처럼 시작 index와 끝 index를 가지고 하나씩 넘어가는 방식으로 구현해줘야 해요!!
var index = filtered.rows.startIndex
while index != filtered.rows.endIndex {
// ...
index = filtered.rows.index(after: index)
}
"나는 Slice 말고 DataFrame으로 쓰고 싶다!!" 라고 하실 수도 있어요.
그럴 땐, Slice를 DataFrame 생성자에 넣어주면 됩니다.
let filtered = DataFrame(dataFrame.filter(on: "Age", Int.self) { $0! >= 60 })
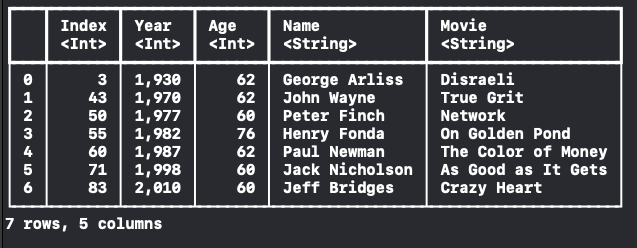
Slice -> DataFrame으로 바꾸면, 시작 index가 0부터 시작하니 주의해주세요!
## 2.7 FormattingOptions
TabulaData는 DataFrame을 테이블 형식으로 콘솔에 출력해주죠??
그런데 출력하는 테이블의 형태를 커스텀 하고 싶다면??
이럴 때 FormattingOptions를 사용합니다.
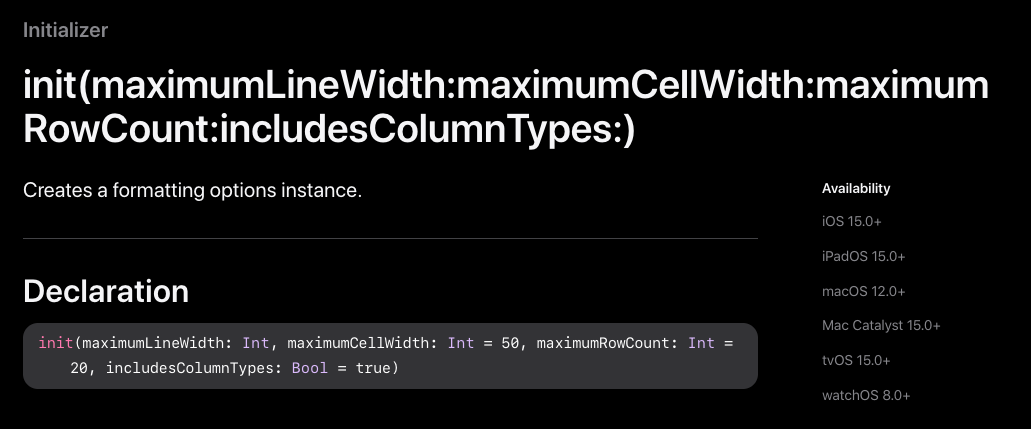
Parameter를 하나씩 살펴볼게요.
- maximumLineWidth : 화면에 출력할 row의 최대 길이
- maximumCellWidth : 화면에 출력할 cell 1개의 최대 길이 (기본값 50)
- maximumRowCount : 화면에 출력할 row의 최대 개수 (기본값 20)
- includesColumnTypes : column의 타입을 출력할지 말지 (기본값 true)
만약 아래처럼 생성했다면,
let formatingOptions = FormattingOptions(
maximumLineWidth: 250,
maximumCellWidth: 20,
maximumRowCount: 10,
includesColumnTypes: false
)
"테이블 한 줄은 250 글자를 넘지 않도록 하고, cell 하나는 20 글자를 넘지 않도록 하고, 화면엔 10개 row만 출력해주고, column 타입은 없어도 돼." 라는 의미예요.
그리고 이렇게 생성한 FormattingOptions를 description method에 넘겨주면 됩니다.
print(dataFrame.description(options: formatingOptions))
## 2.8 Summary
summary method를 사용하면 평균값, 중간값 등등 통계치를 볼 수 있어요.
print(dataFrame.summary(of: "Age"))

## 2.9 Column 합치기
combineColumns라는 method가 있어요.
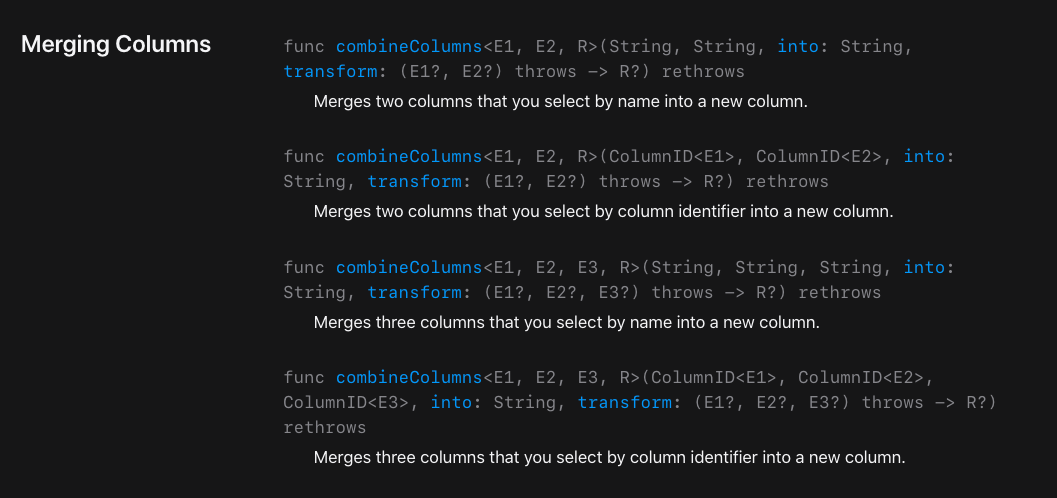
이 method를 사용하면, 2개 또는 3개의 column을 합쳐서 하나의 column으로 만들어줄 수 있어요.
직접 해볼게요.
저희가 처음에 만든 Person 구조체를 사용해서 (Index, Name, Age) Column을 Person이란 Column으로 합쳐볼게요.
struct Person {
var id: Int
var name: String
var age: Int
}
dataFrame.combineColumns("Index", "Name", "Age", into: "Person") { (id: Int?, name: String?, age: Int?) -> Person? in
guard let id = id, let name = name, let age = age else { return nil }
return Person(id: id, name: name, age: age)
}
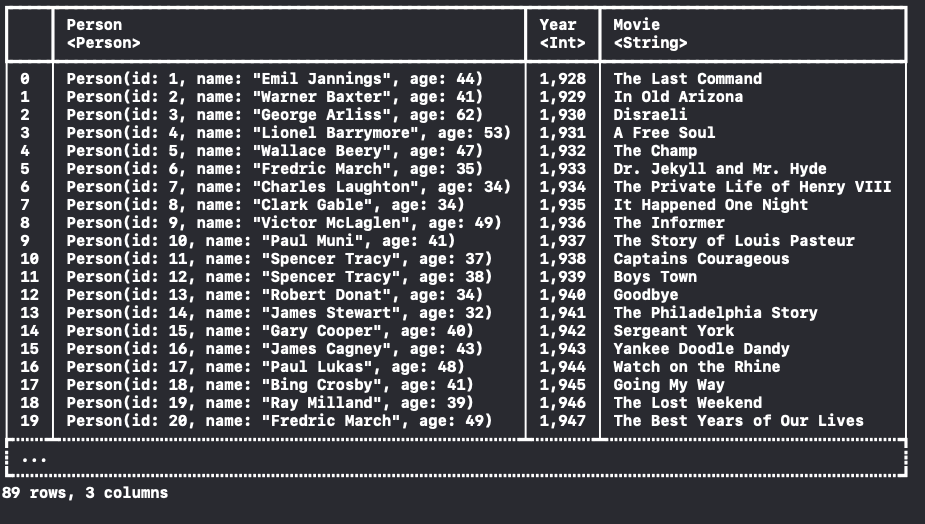
ㅎㅎㅎㅎㅎ.... 👍 👍 👍
## 2.10 Grouping
MySQL GROUP BY와 같은 기능을 제공해주고 있어요.
Age Column을 기준으로 그룹 지어보면,
let grouped = dataFrame.grouped(by: "Age")
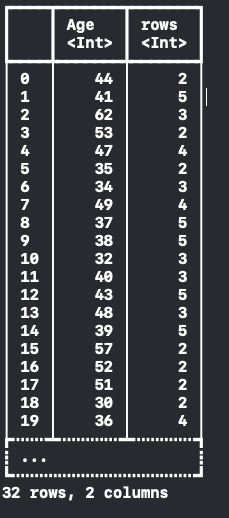
👍 👍 👍
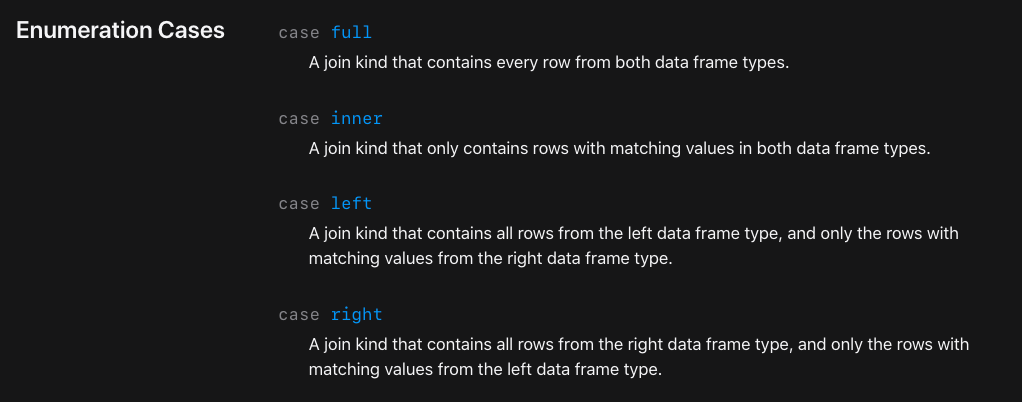
## 2.11 Join
MySQL의 JOIN 기능도 제공해주고 있습니다.
Age > 60을 기준으로 필터링한 filtered dataFrame을 Index Column을 기준으로 join 시켜볼게요.
let filtered = DataFrame(dataFrame.filter(on: "Age", Int.self) { $0! >= 60 })
let joined = filtered.joined(dataFrame, on: "Index")

당연(?)하게도 JoinKind를 통해 join 방식을 정할 수 있습니다.
inner, left outer, right outer, full outer join을 제공해주고 기본값은 inner join이에요ㅎㅎㅎ
# 3. 성능 향상
사실 이런 기능들은 성능이 중요한데요,
이것을 눈치챈 애플에서 성능 향상시킬 수 있는 방법 몇 가지를 소개했어요.
## 3.1 Date parsing
TabulaData는 파일을 읽고 알아서 데이터 타입을 정한다고 했죠?
파일에서 Date 타입을 읽어올 때, 다른 타입(Int, Double) 보다 에러가 발생할 경우도 많고 성능이 좋지 않다고 합니다.
그래서 lazy한 방식을 사용하면 성능 향상에 도움이 된다고 합니다.
lazy한 방식이 뭐냐?
Date 타입을 일단 String 타입으로 읽은 뒤에, 나중에 Date 타입으로 바꿔줘야 할 때 그때 Date 타입으로 바꿔서 사용하라는 의미입니다.
## 3.2 Grouping
Swift 기본 타입(Int, String 등)을 포함한 Column을 기준으로 Grouping 하는 것이 성능에 도움이 된다고 합니다.
그리고, 2개 이상의 Column을 Grouping 해야 한다면, 그 Column 들을 하나의 Column으로 합치고, 합친 Column으로 Grouping을 하면 성능에 좋다고 해요.
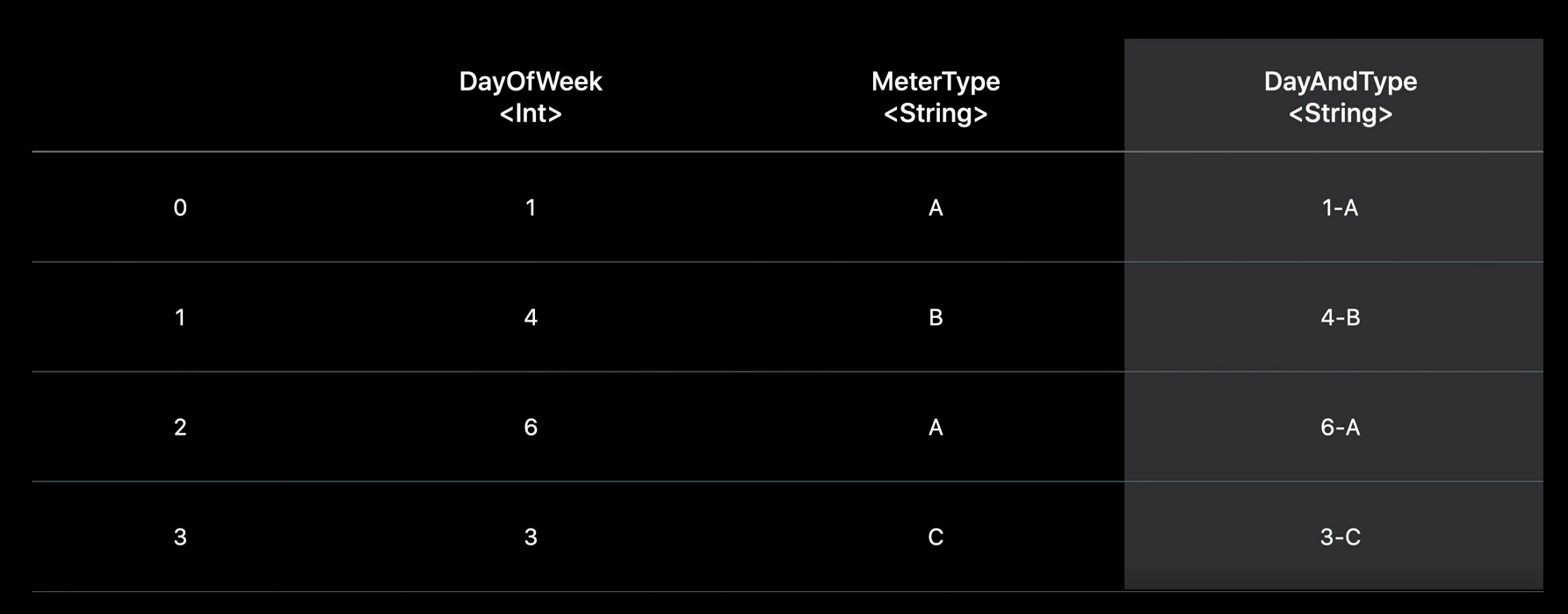
## 3.3 Joining
Grouping과 마찬가지로 Swift 기본 타입을 포함한 Column과 Join을 하면 성능에 도움이 된다고 합니다.
## 참고
- https://developer.apple.com/videos/play/tech-talks/10100/
- https://holyswift.app/crunching-data-with-the-new-apples-tabulardata-framework
TabulaData 프레임워크가 머신러닝을 위해 제공된다고는 하지만
사실 테이블 형식의 데이터를 다루게 될 경우에는 잘 쓰일 것 같다는 생각이 들었어요ㅎㅎ
이번 글은 여기서 마무리.
'iOS' 카테고리의 다른 글
| [오픈소스] Bagbutik (0) | 2022.03.28 |
|---|---|
| mailto scheme과 기본 메일 앱 설정 (0) | 2022.03.23 |
| [오픈소스] CustomDump 소개 (0) | 2022.02.24 |
| Swift Package 의존성 추가, 생성, 배포 방법 (0) | 2022.02.24 |
| SceneDelegate를 제거하는 방법 (0) | 2022.02.05 |